Learning Tools Language Detection
Humans are excellent at recognizing different languages (English, German, Chinese), but unfortunately, computers are not!
For users who speak multiple languages, they can easily open any application (such as email) and just start typing in whatever language they please. The spellchecker may grumble and show errors, but that’s easy for a user to ignore.
Unfortunately, if a student uses the Immersive Reader and types in a language that wasn’t expected, many of the features will work incorrect. Text-to-speech will not pronounce the words corrects, the wrong parts of speech will be shown, etc. This scenario happened regularly for multilingual students and it was a great source of frustration for Immersive Reader users. (Silly computer... can’t you tell that’s German?) The problem becomes even worse if the user switches between multiple languages within the same document.
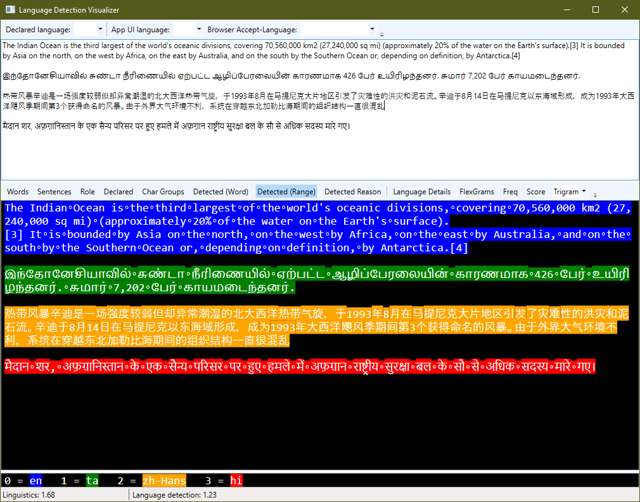
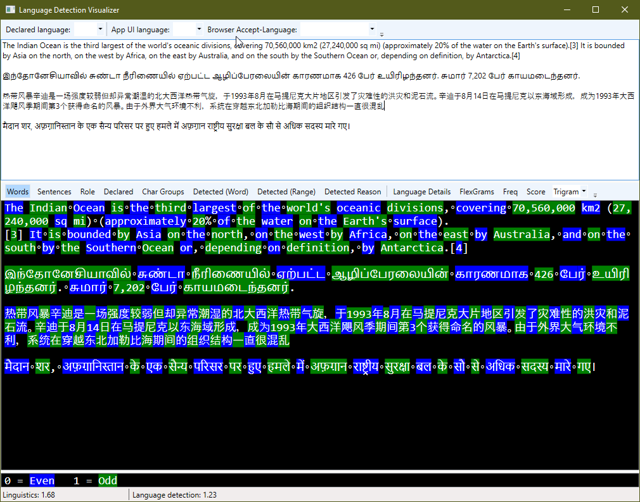
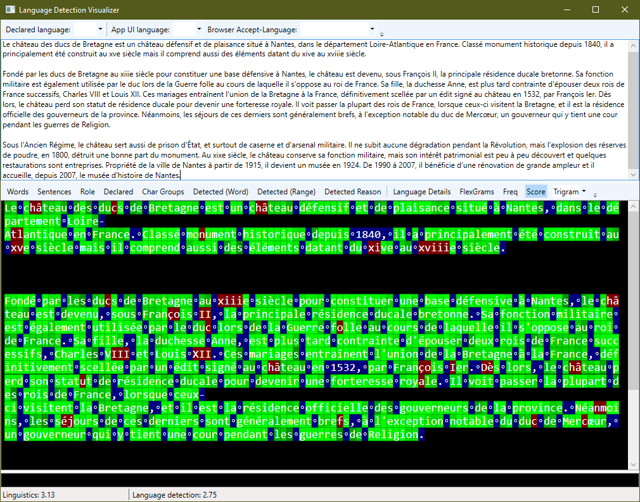
To solve this problem, I implemented a linear regression Language Detection algorithm. The algorithm works as follows:
- First, text is broken down into “Words” and “Sentences” using a language-agnostic algorithm recommended by the World Wide Web Consortium (W3C). This algorithm is not nearly as trivial as one might suspect.
- Each sentence is scanned to determine the types of characters that it contains. Some languages have a unique set of characters (such as Korean, Greek, Thai and Arabic) and the language of a sentence can be determined if the sentence mostly includes those characters.
- For sentences that cannot be determined solely based on their characters, we take each word and break them down into clusters of three-letter groups that are called Trigrams and we compare the statical frequence that each Trigram appears in a document versus how often the Trigram tends to appear in a given language. The closest statistical match wins.
The Immersive Reader is able to detect over 50 languages and the algorithm works very well as long as we have pieces of text that are larger than 50 characters.
- Employer
- Microsoft Corporation
- Role
- Principal Software Engineer
- Focus Areas
- Artificial Intelligence (AI), Natural Language Processing, Language Processing, Globalization, Education
- Technology
- C# 7.0/.NET Standard 1.0, Visual Studio 2017